
柯潔輸?shù)袅伺cAlphaGo的第一戰(zhàn)。而在對戰(zhàn)前的深夜,柯潔在社交網(wǎng)路上發(fā)佈了一篇題為《最後的對決》的文章,充滿了易水訣別般的悲壯感,其中寫道:“現(xiàn)在的AI進(jìn)步之快遠(yuǎn)超我們的想像……我相信未來是屬於人工智慧的。”引發(fā)王思聰在評論區(qū)質(zhì)問:“喲,當(dāng)時李(世石)和AlphaGo下的時候你那囂張勁兒去哪兒去了?”
2016年3月,在韓國棋手李世石以1:4不敵李世石後,這位少年得志的天才棋手確實(shí)曾在微博上撂下豪言“阿爾法狗勝得了李世石,勝不了我”,成為超級網(wǎng)紅。
雖然人類棋手在過去的一年裏努力地研究AlphaGo的套路,試圖找到AlphaGo的弱點(diǎn),但其實(shí),AlphaGo也早已完成更新?lián)Q代,今非昔比。柯潔在賽後發(fā)佈會上表示,AlphaGo和去年判若兩“狗”,去年它的下法還很接近人類,現(xiàn)在感覺越來越接近“圍棋上帝”——圍棋中永不失誤的完美境界。
AlphaGo之父、DeepMind創(chuàng)始人戴密斯·哈薩比斯(Demis Hassabis)也在當(dāng)天的賽後發(fā)佈會上承認(rèn),之前與李世石交手的AlphaGo還是有一些漏洞的,他們在過去的一年裏全力完善演算法,彌補(bǔ)漏洞。
那麼,現(xiàn)在的AlphaGo到底發(fā)生了哪些改變?AlphaGo的研發(fā)公司DeepMind是如何升級它的?5月24日上午,在中國烏鎮(zhèn)人工智慧高峰論壇上,哈薩比斯和AlphaGo團(tuán)隊(duì)負(fù)責(zé)人Dave Silver(戴夫·席爾瓦)揭曉了新一代AlphaGo的奧秘。
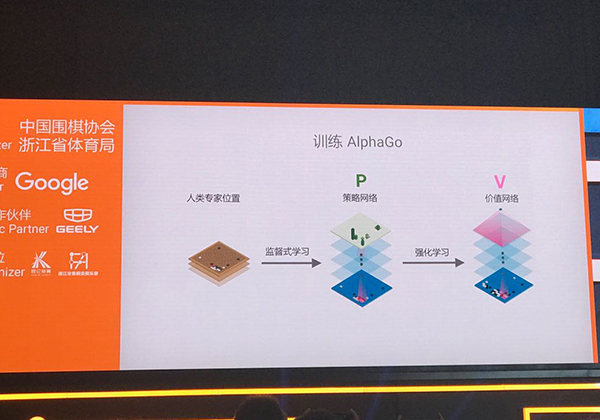
深度強(qiáng)化學(xué)習(xí):降低搜索樹的寬度和深度。本文圖片均來自 澎湃新聞記者 王心馨
這次柯潔面對的AlphaGo大師版,和去年李世石面對的AlphaGo李版主要有三大不同:首先,AlphaGo大師版擯棄人類棋譜,單純向AlphaGo李版的經(jīng)驗(yàn)學(xué)習(xí);其次,AlphaGo大師版的計(jì)算量只有AlphaGo李版的十分之一,只需在單個TPU機(jī)器上運(yùn)作;最後,AlphaGo大師版擁有更強(qiáng)大的策略網(wǎng)路和價值網(wǎng)路。
要理解AlphaGo的演算法,首先要從1997年擊敗西洋棋神話卡斯帕羅夫的“深藍(lán)”演算法説起。西洋棋的每一步都會引出下面三十種可能的走法,棋局的走向就和一棵不斷分出三十個分杈的大樹一樣。而“深藍(lán)”所做的,就是檢索完這棵大樹上的所有分杈,找出當(dāng)下最優(yōu)的那一步。“深藍(lán)”的計(jì)算能力因此能達(dá)到每秒1億個位置,是那個時代的突破性産物。
但到了圍棋這裡,這種蠻力計(jì)算是不可行的。圍棋的每一步牽出的後續(xù)選擇有數(shù)百種。這麼龐大的搜索樹是無法被窮舉的。哈薩比斯説道,比起解構(gòu)性的象棋,圍棋是個建構(gòu)性的遊戲,也更依賴直覺,而非單純的計(jì)算。
而AlphaGo就依賴兩個網(wǎng)路來簡化這棵龐大的搜索樹:降低搜索樹寬度的策略網(wǎng)路和降低搜索樹深度的價值網(wǎng)路。
席爾瓦介紹道,AlphaGo李版首先運(yùn)用策略網(wǎng)路進(jìn)行深度學(xué)習(xí),將大量人類棋譜輸入其中,根據(jù)人類經(jīng)驗(yàn)排除掉搜索樹上一部分的分杈。也就是説,雖然圍棋當(dāng)前的每一步都有上百種可能性,但根據(jù)人類經(jīng)驗(yàn),只有一部分是好的選擇,AlphaGo只需要搜索這些分杈,另一些根本就是“臭棋”。
然後,AlphaGo也不需要在這些分杈上一路搜索到底,模擬到棋盤結(jié)束才知道當(dāng)前這步棋的優(yōu)劣。在當(dāng)前某個特定的選擇往下,AlphaGo只模擬幾步,就能得出一個分?jǐn)?shù)。這個數(shù)值越大,AlphaGo獲勝的概率就越高。那麼,這個數(shù)值是怎麼得出的呢?這就要靠價值網(wǎng)路進(jìn)行強(qiáng)化學(xué)習(xí)。
在強(qiáng)化學(xué)習(xí)中,AlphaGo就根據(jù)策略網(wǎng)路推薦的走法自我對弈,左右互搏,在經(jīng)過反覆自我訓(xùn)練,積累了大量數(shù)據(jù)之後,AlphaGo就能更快地對當(dāng)前走法的勝率有一個概念。
策略網(wǎng)路和價值網(wǎng)路配合形成的深度強(qiáng)化學(xué)習(xí),雖然不能提高AlphaGo的計(jì)算能力(事實(shí)上,AlphaGo每秒計(jì)算1萬個位置,遠(yuǎn)低於“深藍(lán)”),但卻能讓AlphaGo更“聰明”地計(jì)算。
AlphaGo自學(xué)成才:上一代是下一代的老師
而這次柯潔面對的AlphaGo大師版,比起去年李世石面對的AlphaGo李版,最大的不同是在深度學(xué)習(xí)環(huán)節(jié),使用的大量訓(xùn)練數(shù)據(jù)並非人類棋譜,而是AlphaGo李版自我對弈的數(shù)據(jù)。


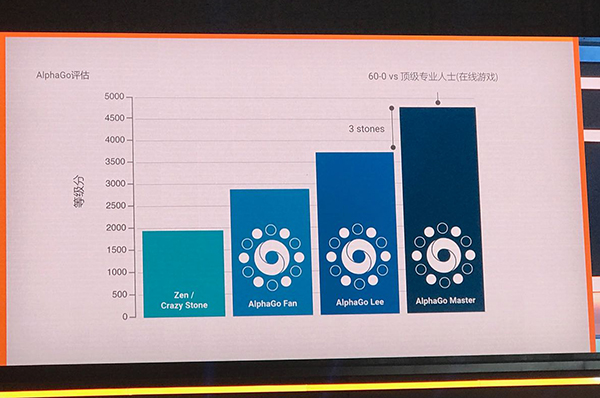
AlphaGo大師版對比AlphaGo李版三大升級。
席爾瓦説道:“AlphaGo大師版能如此高效運(yùn)算的最主要原因是,我們使用了最好、最可用的數(shù)據(jù)來訓(xùn)練它。我們所説的最好的數(shù)據(jù)不是來自於人,而是來自於AlphaGo自己。AlphaGo現(xiàn)在等於説是自學(xué)成才。我們讓它自己當(dāng)自己的老師,而這一代的AlphaGo也會成為下一代AlphaGo的老師。”
汲取了大量自我學(xué)習(xí)的經(jīng)驗(yàn),這次與柯潔交手的AlphaGo大師版的策略網(wǎng)路和價值網(wǎng)路也因此更為強(qiáng)大。這大大提高了AlphaGo的運(yùn)算效率 ,把計(jì)算量縮減到對戰(zhàn)李世石時的十分之一。從硬體來看,AlphaGo李版在下棋時還需要50個TPU(谷歌專為加速深層神經(jīng)網(wǎng)路運(yùn)算能力而研發(fā)的晶片),AlphaGo大師版現(xiàn)在和柯潔對戰(zhàn)時只需要1個TPU。
而更強(qiáng)大的AlphaGo大師版又會帶來更優(yōu)秀的數(shù)據(jù),以訓(xùn)練下一代AlphaGo。這是一個良性迴圈。
AlphaGo的迭代增強(qiáng)。
哈薩比斯説道,AlphaGo的首要目標(biāo)還是要“追求完美”。在過去的數(shù)千年,人類都沒有達(dá)到圍棋的真理境界。他希望,AlphaGo能和人類共同努力,趨近圍棋真理。
[責(zé)任編輯:郭曉康]
 京ICP證130248號京公網(wǎng)安備110102003391網(wǎng)路傳播視聽節(jié)目許可證0107219號
京ICP證130248號京公網(wǎng)安備110102003391網(wǎng)路傳播視聽節(jié)目許可證0107219號
